

Autor textu MediaGuru
Look-alike modely mohou být užitečným nástrojem, je ale třeba porozumět
tomu, jak segmenty vznikají a jakou přesnost od nich můžeme očekávat,
píše Jiří Udatný.
Za jednu z výhod online oproti offline reklamě se často uvádí přesnost jejího cílení. Vsaďte boty, že vám tuto vlastnost zmíní 9 z 10 lidí pracujících v marketingu a vy jste možná jeden z nich. Jako argument se používá tvrzení, že v online prostředí lze díky obrovskému množství dat oslovit přímo konkrétního zákazníka, zatímco v offline světě je nutné oslovovat plošně všechny lidi bez rozdílu. Online reklama se zdá být v tomto smyslu neporazitelná. Je tomu ale opravdu tak?
Ponechme stranou výkonově orientované kampaně, kde přesnost cílení je vedlejší. Jejich primárním cílem je doručení výkonových kritérií a bývá přitom často jedno, v rámci jaké skupiny uživatelů. Anebo to jedno není, pak však pro ně platí to, co pro kampaně brandové. V brandových kampaních je totiž cílení, resp. doručení sdělení definované cílové skupině, kde jsme identifikovali obchodní potenciál, jejich samotnou podstatou. Využít lze dat přímo z jednotlivých reklamních platforem, kde reklama běží. Jiná data má o svých uživatelích Facebook, jiná Google, jiná Seznam. Zatímco Seznam s Googlem disponují např. detailními daty o tom, co uživatelé vyhledávají, Facebook těží informace z aktivity uživatelů v rámci své sociální sítě. Heureku zase bude obtížné trumfnout v detailu dat o nákupních úmyslech. V online reklamě se však využívají i data agregovaná, která popisují nikoliv jednotlivé uživatele, nýbrž strukturu uživatelů daného webu jako celku. To je typické pro tzv. přímý nákup a jedná se o nejjednodušší princip tzv. afinitního cílení, jak ho známe z offline světa. Pokud je však cílem dosáhnout významnějšího zásahu přesahujícího hranice jednoho dodavatele reklamního prostoru, mít možnost efektivně řídit frekvenci a k cílení využívat data svoje či třetích stran, přichází do hry programatický způsob nákupu reklamního prostoru, typicky RTB (Real Time Bidding).
Efektivní využití dat pro cílení se často skloňuje právě v souvislosti s programaticky nakupovanou online reklamou prostřednictvím RTB. A jak je tedy přesné cílení v programatiku? Na rozdíl od tzv. přímého nákupu se mezi jeho výhody uvádí právě možnost oslovit konkrétního zákazníka, nikoli plošně všechny uživatele, kteří chodí na daný web. Nelze zpochybnit fakt, že množství a detail dat, která za sebou v online prostředí zanecháváme, je obrovské. Svojí aktivitou v internetovém prohlížeči o sobě dalším subjektům předáváme informace o svém zařízení a jeho vlastnostech, kdy a kde se nacházíme, co vyhledáváme, co čteme, co nakupujeme apod.
Pokud tato data využíváme pro tzv. deterministické cílení, což lze chápat jako cílení na základě dat, která o daném uživateli známe (např. časové, geografické, technografické, kontextové, behaviorální či retargeting), pak je přesnost cílení ze své podstaty 100%. Pro spoustu případů však toto neplatí. V čem je háček? Jedná se totiž o data, která neexistují (anebo je nemáte k dispozici právě vy) k dostatečnému počtu uživatelů pro dosažení relevantního zásahu vaší kampaně. Můžeme začít obyčejnou socio-demografií, pokračovat přes vlastnosti návštěvníků vašeho webu, nákupčí konkrétního produktu z vybraného e-shopu či nepřeberné množství „offline“ dat, jako jsou různé názory, postoje, preference či chování mimo síť, které lze získat např. z online dotazníkových výzkumů. Všechny tyto charakteristiky mohou být zajímavé pro cílení v online prostředí, ale máte je typicky k dispozici jen k omezenému počtu uživatelů. Díky tomu nestačí zacílit pouze uživatele, o kterých dané vlastnosti víte (např. že jsou muži v určitém věku), ale musíte si pomoci jinak.
Cestou je pokusit se požadované publikum rozšířit, tj. najít další uživatele, o kterých sice danou charakteristiku neznáte, ale vykazují podobné vlastnosti (čtěte „podobné internetové chování”), jako uživatelé, o kterých je tato informace k dispozici. K tomu se používá tzv. look-alike modelování, což je označení pro soubor k tomuto určených různorodých dataminingových technik. Výsledkem takového look-alike publika je pak skupina uživatelů, o kterých algoritmus rozhodl, že s určitou mírou pravděpodobnosti patří do požadovaného cílového publika, proto mluvíme o pravděpodobnostním cílení. Slovo „pravděpodobnost” je v tomto ohledu naprosto zásadní. Míra této pravděpodobnosti dělá pak výsledné publikum více či méně kvalitní, tedy přesné.
Pokud někdo prodává publika, měl by být schopen k nim dodat i metriky vyjadřující přesnost jejich cílení.
Pokud nemáte možnost tvořit si tímto způsobem publika sami nebo někoho, kdo vám je vytvoří, není dnes problém si hotové již koupit od celé řady subjektů jako je Seznam, CPEx a další např. v AdForm Audience Marketplace. Kromě samotného poskytovatele se publika na první pohled liší svojí cenou a také velikostí. Ale jak se liší jejich kvalita, tedy přesnost? Nevíte. Kupujete tedy zajíce v pytli. Výsledky poznáte vždy až ex-post, tj. po kampani, resp. v jejím průběhu, pokud na daném cílení odběhne významnější část kampaně, která vám umožní výsledky vyhodnotit. Ale co je tím vhodným kritériem? Vyhodnotit dopad kampaně přímo na značku vyžaduje další měření a také peníze. Navíc v tom hraje obrovskou roli kvalita kreativy. Vyhodnocovat přesnost cílení podle výkonových kritérií může být také značně zavádějící. Např. vyšší CTR ještě nemusí být příznakem kvalitního cílení. Co když reagovala část publika, která vůbec nebyla záměrnou součástí cílového publika, ale vám se jí podařilo nechtěně oslovit? Cílení tak mohlo být vlastně úplně špatně včetně špatného předpokladu o vhodné cílové skupině. Jediným nezpochybnitelným kritériem kvalitního publika je tak schopnost doměřit tzv. on-target imprese, tzn. imprese, které byly zobrazeny zamýšlené cílové skupině, případě on-target zásah, tedy uživatele patřící do cílové skupiny.
Jak by se mohlo na první pohled zdát, není však podstatný pouze absolutní podíl těchto impresí či uživatelů v kampani. Pokud cílová skupina představuje např. 60 % online populace, pak 60% podíl on-target zásahu není pro cílení příliš lichotivý výsledek. Stejných 60 % on-target zásahu pro publikum, které čítá pouze 30 % v populaci, to je naopak výsledek velmi dobrý, neboť jste byli díky cílení 2x přesnější. Z toho vyplývá, že kromě relativního podílu on-target zásahu je nutné sledovat podíl těchto uživatelů vůči velikosti cílového publika. Tento podíl pak představuje skutečné měřítko kvality look-alike modelu a lze na něj nahlížet jakožto na afinitu, která je běžně používaným kritériem kvality cílení v offlinových mediatypech, např. v televizi. A stejně jako v televizi má afinita přímou vazbu na cenovou efektivitu, je tomu tak stejně i v tomto případě. Jakékoli cílení dává smysl jen tehdy, pokud podíl částky, kterou zaplatíte za cílenou kampaň a částky za kampaň bez cílení, je menší než výše zmíněná afinita. V opačném případě je vždy výhodnější široký plošný zásah bez jakéhokoli cílení.
Kvalitu cílového publika od konkrétního poskytovatele lze tedy zjistit v zásadě dvěma způsoby. První možnost je, že vám ji konkrétní poskytovatel prozradí. Pokud někdo prodává publika, měl by být schopen k nim dodat i metriky vyjadřující přesnost jejich cílení. Pokud to poskytnout neumí nebo nechce, je to varovný signál pro vás. Druhou možností je provést si nezávislé měření kampaně, kde takové publikum využijete. Možností je na trhu celá řada (např. GroupM mProfile, Nielsen DAR, Gemius AdAudit). Ať už tak, nebo tak, není to věc samozřejmá a stojí čas a peníze. Navíc v případě některých nástrojů možnosti vyhodnocení často končí u základní socio-demografie. Proto alespoň nabízím dvě základních pravidla, která představují nutné, nikoliv však postačující podmínky kvalitního look-alike publika. Jejich splnění tedy automaticky nezaručí kvalitní cílení, ale na druhou stranu minimálně vyloučí ta zjevně nekvalitní.
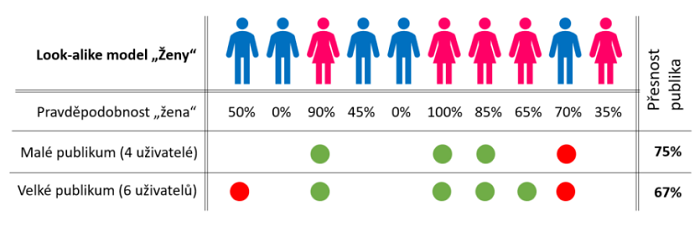
Přesnost cílení s velikostí pravděpodobnostních publik klesá.
Čím větší publikum vám někdo nabízí, tím více byste se měli mít na pozoru. Přesnost cílení totiž s velikostí pravděpodobnostních publik klesá. Velmi často se však velikost cílového publika tvoří s ohledem na jeho velikost v populaci. To je ale obrovský omyl.
Na ilustraci níže je výše uvedené pravidlo demonstrováno na příkladu look-alike modelu pro ženy. Každému uživateli, u kterého pohlaví neznáte, ale máte k němu dostatek dat o jeho internetovém chování, model spočítá míru pravděpodobnosti, že daný uživatel je „žena”. Vychází tak z podobnosti internetového chování těchto uživatelů a části uživatelů, u kterých tuto informaci znáte. U některých uživatelů to model odhadne velmi přesně, u některých se může plést. Výsledné publikum pak tvoříte tak, že si uživatele seřadíte podle této pravděpodobnosti a určíte si požadovanou přesnost. Zde do hry vstupuje již zmíněná velikost publika v populaci, cena daného cílení a také velikost kampaně, pro kterou publikum tvoříte. Nicméně je zcela zřejmé, že čím více publikum rozšiřujete, tím jeho přesnost klesá.
Zamýšleli jste se někdy nad tím, jaký dopad má na kvalitu cílení kombinování cílových publik ve vaší kampani? Chcete-li cílit např. na muže ve věku 25-40 let, musíte si koupit typicky cílová publika dvě: muže a lidi v daném věku. Obě skupiny v kampani následně zkombinujete logickým operátorem „A”. Vynásobte si však přesnosti obou publik mezi sebou, logicky dostanete ještě nižší přesnost, než je přesnost toho horšího z obou publik. Navíc modelovat všechny muže, jinými slovy odhadovat odděleně pohlaví uživatele (kde jsou mladí i staří) a věk (kde jsou ženy i muži) na základě internetového chování uživatele, je vždy složitější a méně přesné než modelovat výrazně homogennější skupinu mužů v konkrétním věkovém intervalu. Vždy tedy chtějte publikum, které je vytvořeno na míru vašim potřebám a nekombinujte hotová publika až ve vaší kampani. Bude to mít vždy za následek nižší přesnost cílení.
Look-alike modely mohou být velmi užitečným nástrojem pro tvorbu kvalitních cílových publik pro programaticky nakupované displayové kampaně, ale je potřeba rozumět tomu, jak segmenty vznikají a jakou přesnost od nich můžeme očekávat. Jinak mohou být jen iluzí efektivního cílení a černou dírou pro vaše peníze. Ne vše se dá na internetu spolehlivě cílit jen proto, že je to na internetu. Vždy chtějte od svého poskytovatele znát detaily nakupovaných publik, původ dat, na kterých byly odvozeny a nezapomeňte: „nejen na velikosti záleží”.
Autor textu: Jiří Udatný, Data & Analytics Director, GroupM
Autor textu MediaGuru


V prvním pololetí roku 2026 skupina Mafra realizovala více než
1 250 reklamních formátů na sociálních sítích pro téměř
400 klientů. Roste zájem o kampaně propojující obsah, mediální značky
a výkon digitálních kanálů.

Platforma Forendors, která umožňuje tvůrcům zpoplatnit digitální obsah
prostřednictvím předplatného, funguje na trhu pět let. Za tuto dobu
získala více než 1700 tvůrců a podle svých údajů jim vyplatila přes
200 milionů Kč. Do dalšího období se chce zaměřit také na podporu
živých akcí a budování komunit mimo online prostředí.

Nová vrstva umožní klientům a partnerům vytvářet vlastní AI agenty nad
reklamní infrastrukturou firmy a propojit data, nákup i prodej reklamy.